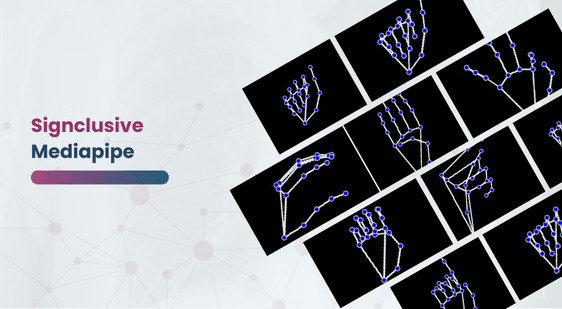
The data collection process for the Signclusive Mediapipe dataset involved gathering images from five different signers, each contributing 100 samples per letter of the alphabet and the “space” sign, resulting in 500 samples per letter and a total of 13,500 images. Each image was originally captured at a resolution of 640×480 pixels and later resized to 224×224 pixels to meet the input requirements for neural network training. This resizing ensured consistency and compatibility across the dataset. Additionally, the images were processed using the Mediapipe framework to detect and highlight hand landmarks, with the background blacked out to focus the model’s attention solely on the hand features, enhancing the model’s ability to accurately recognize and learn from the sign language gestures.